在做统计分析功能时,最初的方案是通过 RPC 调用业务服务接口取数据,结果遇到了两个问题:一是接口耦合度太高,业务变更容易影响统计;二是在数据量大时,实时调用的性能不够理想。
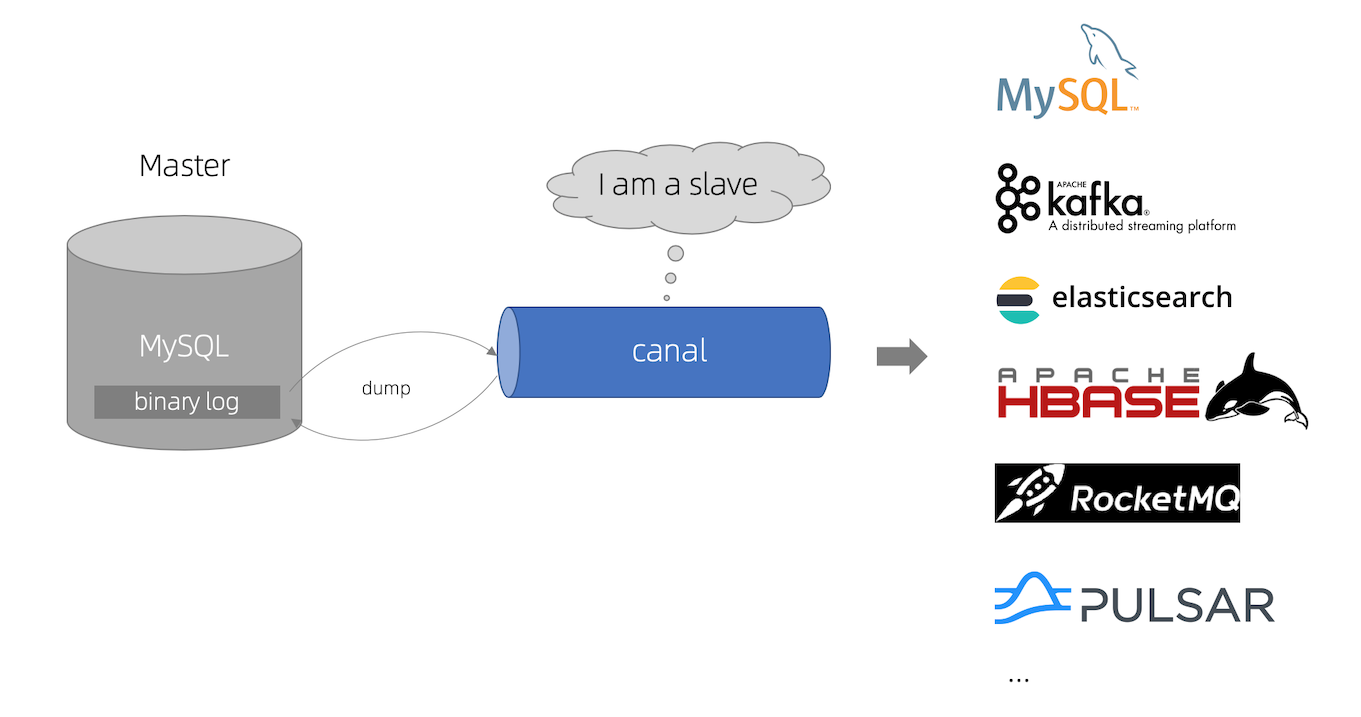
后来换了一种思路——通过监听 MySQL 的 binlog,将业务库的数据变更实时同步到统计库,统计服务只查自己的库,彻底解耦。Canal 就是实现这个思路的工具,阿里开源的,基于模拟 MySQL 主从复制的原理。
Canal 的工作原理
Canal 把自己伪装成 MySQL 的从库(Slave),向主库发送 SHOW MASTER STATUS 请求,然后持续接收 binlog 数据流。业务库的每一条增删改操作,都会被 Canal 捕获,再由 Canal 客户端消费并处理。
所以使用 Canal 的前提是:MySQL 必须开启 binlog,且格式为 ROW 模式。
MySQL 环境准备
1. 开启 binlog
在 MySQL 配置文件 my.cnf 中追加:
[mysqld]
server_id=1
log-bin=mysql-bin
binlog_format=ROW
expire_logs_days=7
binlog-ignore-db=mysql
|
修改后重启 MySQL,验证:
mysql> SHOW VARIABLES LIKE 'log_bin';
+
| Variable_name | Value |
+
| log_bin | ON |
+
|
2. 创建 Canal 专用账号
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT SHOW VIEW, SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
|
生产环境建议把密码改复杂一点,不要真用 canal/canal。
Docker 部署 Canal
mkdir -p /mydata/canal/example
touch /mydata/canal/example/instance.properties
docker run -p 11111:11111 --name canal \
-v /mydata/canal/example/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-d canal/canal-server
|
常见坑:如果 -v 映射的宿主机路径不存在,Docker 会自动创建成目录,导致报错 Are you trying to mount a directory onto a file?。解决方式是先 touch 创建文件,再挂载。
修改实例配置
vi /mydata/canal/example/instance.properties
|
canal.instance.master.address=172.16.0.8:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.filter.regex=business_db\\.member
|
修改后重启 Canal 容器使配置生效。
Spring Boot 接入 Canal
1. 添加依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
|
2. 配置目标数据库
spring.datasource.url=jdbc:mysql://localhost:3306/stat_db?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=your_password
|
3. Canal 客户端实现
核心是连接 Canal Server,轮询拉取变更消息,解析每条 binlog entry,根据事件类型(INSERT/UPDATE/DELETE)构造目标库的 SQL 并执行:
@Component
public class CanalClient {
private final Queue<String> sqlQueue = new ConcurrentLinkedQueue<>();
@Resource
private DataSource dataSource;
public void run() {
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("192.168.0.58", 11111),
"example",
"canal",
"canal");
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(1000);
long batchId = message.getId();
if (batchId == -1 || message.getEntries().isEmpty()) {
Thread.sleep(1000);
} else {
processEntries(message.getEntries());
}
connector.ack(batchId);
if (!sqlQueue.isEmpty()) {
executeQueuedSql();
}
}
} catch (Exception e) {
log.error("Canal client error", e);
} finally {
connector.disconnect();
}
}
private void processEntries(List<Entry> entries) throws InvalidProtocolBufferException {
for (Entry entry : entries) {
if (entry.getEntryType() != EntryType.ROWDATA) continue;
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
String tableName = entry.getHeader().getTableName();
switch (rowChange.getEventType()) {
case INSERT -> buildInsertSql(tableName, rowChange).forEach(sqlQueue::add);
case UPDATE -> buildUpdateSql(tableName, rowChange).forEach(sqlQueue::add);
case DELETE -> buildDeleteSql(tableName, rowChange).forEach(sqlQueue::add);
}
}
}
private List<String> buildInsertSql(String table, RowChange rowChange) {
List<String> sqls = new ArrayList<>();
for (RowData rowData : rowChange.getRowDatasList()) {
List<Column> cols = rowData.getAfterColumnsList();
String fields = cols.stream().map(Column::getName).collect(Collectors.joining(","));
String values = cols.stream()
.map(c -> c.getValue().isEmpty() ? "NULL" : "'" + c.getValue() + "'")
.collect(Collectors.joining(","));
sqls.add(String.format("INSERT INTO %s (%s) VALUES (%s)", table, fields, values));
}
return sqls;
}
private List<String> buildUpdateSql(String table, RowChange rowChange) {
List<String> sqls = new ArrayList<>();
for (RowData rowData : rowChange.getRowDatasList()) {
List<Column> newCols = rowData.getAfterColumnsList();
String setClause = newCols.stream()
.map(c -> c.getName() + "='" + c.getValue() + "'")
.collect(Collectors.joining(","));
String whereClause = rowData.getBeforeColumnsList().stream()
.filter(Column::getIsKey)
.map(c -> c.getName() + "=" + c.getValue())
.findFirst()
.orElse("1=0");
sqls.add(String.format("UPDATE %s SET %s WHERE %s", table, setClause, whereClause));
}
return sqls;
}
private List<String> buildDeleteSql(String table, RowChange rowChange) {
List<String> sqls = new ArrayList<>();
for (RowData rowData : rowChange.getRowDatasList()) {
String whereClause = rowData.getBeforeColumnsList().stream()
.filter(Column::getIsKey)
.map(c -> c.getName() + "=" + c.getValue())
.findFirst()
.orElse("1=0");
sqls.add(String.format("DELETE FROM %s WHERE %s", table, whereClause));
}
return sqls;
}
private void executeQueuedSql() {
while (!sqlQueue.isEmpty()) {
String sql = sqlQueue.poll();
try (Connection con = dataSource.getConnection()) {
new QueryRunner().execute(con, sql);
} catch (SQLException e) {
log.error("Execute sql failed: {}", sql, e);
}
}
}
}
|
4. 应用启动时触发监听
@SpringBootApplication
public class CanalApplication implements CommandLineRunner {
@Resource
private CanalClient canalClient;
public static void main(String[] args) {
SpringApplication.run(CanalApplication.class, args);
}
@Override
public void run(String... args) {
new Thread(canalClient::run).start();
}
}
|
注意事项
- binlog 格式必须是 ROW:STATEMENT 格式下 Canal 无法拿到字段级别的变更数据。
- server_id 不能重复:Canal 的 slaveId(默认 1234)不能与 MySQL 主库的 server_id 相同,否则连接会被拒绝。
- 生产环境的 SQL 构建方式:上面的 SQL 拼接是示例写法,生产中建议用 PreparedStatement 避免注入风险,或者根据表结构做更精细的处理。
- 数据一致性保证:Canal 拉取是通过
getWithoutAck + ack 实现的,如果消费端处理失败没有 ack,下次重启会重新消费,需要做幂等处理(通常用主键做 INSERT ... ON DUPLICATE KEY UPDATE)。 - 表结构同步问题:Canal 只同步数据,不同步 DDL(建表、改字段等),目标库需要提前建好结构。