
EasyExcel 百万数据读写记录平台每月月末,财务都要把当月全量销售订单行数据导出给 ERP 做对账,同时线下渠道也会反向导入一批补录数据。每月订单行约 120 万条,每行包含订单号、SKU 编码、数量、单价、实付金额、渠道、仓库等十几个字段。 第一版用 POI 的 WorkbookFactory.create() 直接读,跑到 60 万行时内存撑不住,OOM 了。换 EasyExcel 后同样的文件峰值内存降到 200MB 以内,120 万行跑完没有任何问题。 一、为什么从 POI 换到 EasyExcelPOI 读取 Excel 有两种模式: DOM 模式(WorkbookFactory.create()):把整个文件加载进内存再遍历处理。文件小没问题,大文件直接 OOM SAX 模式(XSSFReader):流式解析,逐行回调。内存占用小但 API 极其繁琐,需要自己处理 XML 解析细节 EasyExcel 底层用的就是 POI SAX 模式,但封装了简洁的监听器 API,不用处理任何 XML 细节。 核心优势:不把整个文件加载进内存,无论文件多大,内存占用基本恒定, ...
技术学习
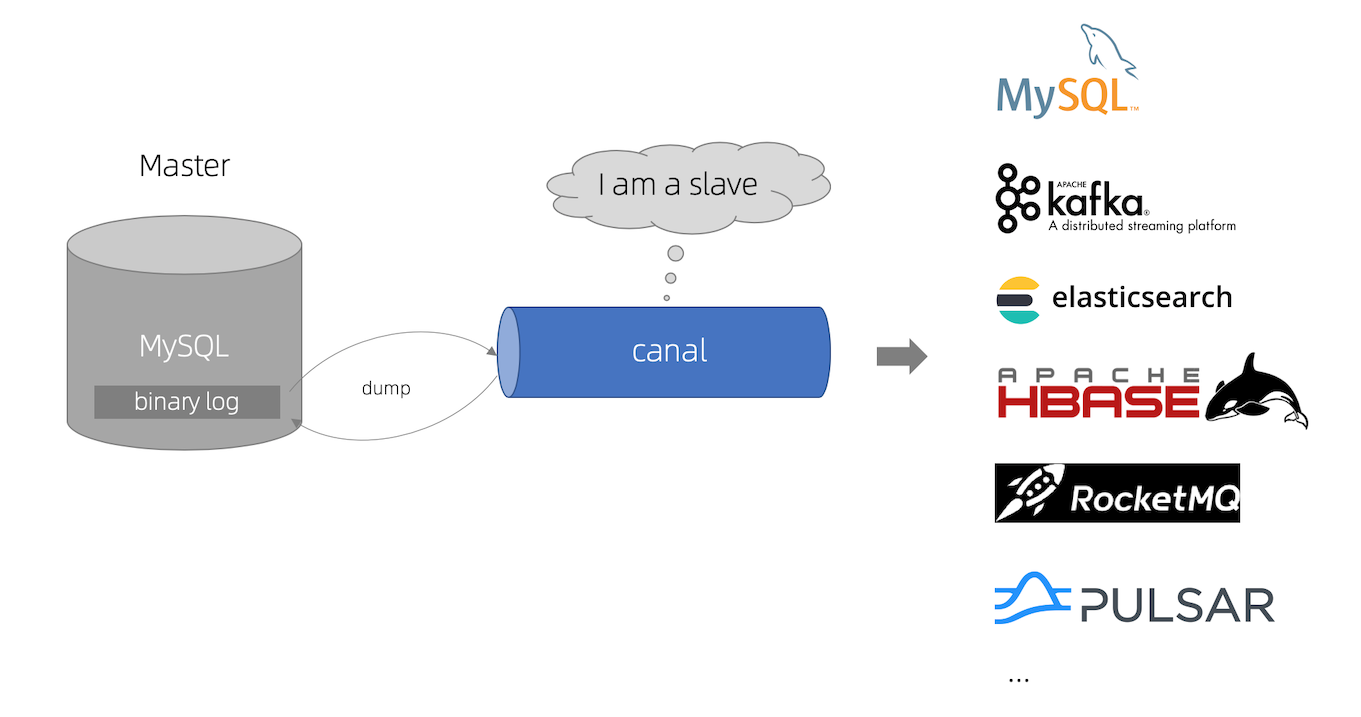
未读在做统计分析功能时,最初的方案是通过 RPC 调用业务服务接口取数据,结果遇到了两个问题:一是接口耦合度太高,业务变更容易影响统计;二是在数据量大时,实时调用的性能不够理想。 后来换了一种思路——通过监听 MySQL 的 binlog,将业务库的数据变更实时同步到统计库,统计服务只查自己的库,彻底解耦。Canal 就是实现这个思路的工具,阿里开源的,基于模拟 MySQL 主从复制的原理。 Canal 的工作原理Canal 把自己伪装成 MySQL 的从库(Slave),向主库发送 SHOW MASTER STATUS 请求,然后持续接收 binlog 数据流。业务库的每一条增删改操作,都会被 Canal 捕获,再由 Canal 客户端消费并处理。 所以使用 Canal 的前提是:MySQL 必须开启 binlog,且格式为 ROW 模式。 MySQL 环境准备1. 开启 binlog在 MySQL 配置文件 my.cnf 中追加: [mysqld]server_id=1 # 实例 ID,不能与 Canal 的 slaveId 重复log-bin=mysql ...
裁员潮里,我对”技术人的护城河”的新理解一、寒冬的真实感受2022 年夏天,有个大学同学发消息问我,他们公司在谈补偿,他想聊聊接下来怎么办。 他在一家互联网公司做后端,工作了五年多,技术方向是公司内部的业务中台。我们聊了一个多小时,他说的一句话我印象很深:他们中台的技术方案都是公司特有的,外面几乎用不上,投了几份简历,面试问的东西他都没怎么接触过。 那段时间这样的消息不少。有人是主动离职在找机会,有人是被优化,有人是因为部门整合被”平移”到了一个没什么前途的岗位上。行业在降温,这件事对所有人来说都是真的,不是谣言,不是夸大。 我也开始认真审视自己的处境。 二、我观察到的规律被影响最大的,大致有这样几类特征: 技术过于垂直单一。 只用过公司内部的框架和工具,比如某个公司自研的 RPC、配置中心,离开这家公司这些技能没有流通价值。 停留在执行层,未参与决策。 做了很多年,但一直是接任务、写代码,没有参与过设计方案、技术选型或者业务判断。一旦需要向外部证明自己的能力,能展示的只有”我在 XX 公司做了 XX 项目”,而不是”我能设计 XX 类型的系统”。 知识依赖特定上下文。 熟悉某个业务的 ...
技术学习
未读Java 函数式接口实战笔记用 Lambda 表达式写了两三年,但真正把函数式接口理清楚是在一次代码 Review 上。同事指出我用 if-else 写的一段多策略逻辑可以用 Map<String, Function> 完全替代。回头一看,才发现自己对 Function、Consumer、Supplier、Predicate 的区别一直停留在”会用”,没真正整理过。这篇做个梳理,重点放在业务场景里真实用到的地方。 一、四大接口速查Java 8 的 java.util.function 包里预置了几十个函数式接口,但日常开发 90% 的场景都落在这四个上: 接口 方法签名 记忆口诀 典型场景 Function<T, R> R apply(T t) 有入有出,做转换 对象属性提取、类型转换、格式化 Consumer<T> void accept(T t) 有入无出,做消费 遍历处理、打印日志、调用外部接口 Supplier<T> T get() 无入有出,做生产 懒加载、默认值兜底、工厂方法 Predicate< ...
ElasticSearch 使用记录项目有全文搜索需求,MySQL 的 LIKE 查询太慢,上了 ElasticSearch。记录安装和接入过程,主要踩坑在权限问题和 ik 分词器版本匹配上。 ElasticSearch 是一个分布式、可扩展、实时的搜索与数据分析引擎,能从项目一开始就赋予数据搜索、分析和探索的能力,可用于全文搜索和实时数据统计。 安装Linux(Docker) 修改虚拟内存区域大小,否则 ES 启动会失败: sysctl -w vm.max_map_count=262144 启动容器(注意替换版本号): docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \ -e "discovery.type=single-node" \ -e "cluster.name=elasticsearch" \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -v /mydat ...
DDD 落地一年:我们用了什么,丢掉了什么网上关于 DDD 的文章,大部分要么在介绍概念(什么是聚合根、限界上下文、领域事件),要么在讲成功案例(我们用了 DDD 之后系统多清晰多优雅)。 这篇不是那种文章。 我想写的是:我们团队实践 DDD 一年之后,真实的状态是什么。用了什么,没用什么,有哪些确实有帮助,有哪些折腾完之后发现是自找麻烦。 一、为什么开始用 DDD不是主动跟风,是被问题逼的。 大概是 2021 年底,项目已经跑了三四年,代码量很大,新需求改动一个地方往往会影响到另外几个地方,改 bug 经常改出新 bug。主要的问题是:核心业务逻辑散落在各处,同一个概念在不同模块里有不同的名字和实现,模块之间的边界模糊。 那段时间我们做了一次架构复盘,讨论到”怎么给系统划清楚边界”时,有人提到了 DDD。于是开始认真研究了一下。 二、我们实际落地的内容大概花了两个月看资料、讨论,然后开始在一个新模块里尝试落地。 落地了的: 限界上下文。这是 DDD 里落地起来最轻的一个概念,也是最有实际价值的。我们做的事情很简单:画了一张图,明确哪些业务概念属于哪个模块,跨模块的调用只能走接口, ...
Spring Cloud Gateway 聚合 Swagger 接入记录微服务拆了七八个服务之后,每次前端联调就开始抱怨:每个服务跑在不同端口,要开一排浏览器 Tab,搞不清哪个端口对应哪个模块。其实后端自己调试接口时也一样烦。 网关聚合 Swagger 解决的就是这个问题:所有服务的接口文档统一在网关入口访问,下拉切换服务,不用换页面也不用记端口。 一、为什么需要网关聚合没有聚合时的状态: 订单服务 Swagger:http://localhost:8081/swagger-ui/index.html 用户服务 Swagger:http://localhost:8082/swagger-ui/index.html 商品服务 Swagger:http://localhost:8083/swagger-ui/index.html 测试环境 IP 加端口号记不住,每次联调都要找人要地址。 聚合后的效果:统一访问 http://gateway-host/swagger-ui/index.html,顶部下拉选择服务名,接口文档即时切换。 二、技术选型 springfox:老方案,3.x ...
一次让我想清楚很多事的系统重构一、旧系统的状态说”旧”其实不太准确,那个系统当时只跑了三年,但三年里业务扩展了好几倍,代码已经是另一种状态了。 症状很典型:一个”订单处理”的 Service 类,里面有 4000 行代码,涉及下单、支付回调、退款、对账、库存扣减。这些逻辑本来应该属于不同的域,但随着需求一个个加进来,全都堆在了这个文件里。 改一个需求要修改几个地方,改完之后不知道会影响哪里,上线前的自测范围越来越大,测试同学每次回归都说”你这次改了什么,我要全测一遍”。 有一个痛点最直观:产品提了一个需求,要支持”先货后款”的付款方式,和原有逻辑有交叉。我评估工时写了”5天”,组长皱了皱眉说”有那么复杂吗”——但不是因为我在虚报,是因为我真的搞不清楚改动的影响范围。 二、改造的动机重构这件事是我主动提的,时间节点大概是 2022 年初。 触发点是一次需求评审,产品提了一个新的业务方向——多渠道订单聚合,简单说就是把不同来源的订单统一进来。我在脑子里过了一遍,发现要改的地方太多了,而且那些地方都互相依赖,我说不清楚改完之后系统还是不是稳的。 我提了重构方案,理由是:我们现在的系统结构已经 ...
技术学习
未读MongoDB 使用记录项目里有一块访问日志需要存储,数据量大、结构灵活,不想为此专门建 MySQL 表,就选了 MongoDB 来存。这是当时接入时整理的笔记。 MongoDB 是为快速开发互联网 Web 应用而构建的数据库系统,其数据模型和持久化策略专为高读/写吞吐量和高自动灾备伸缩性场景设计。 安装Windows 下载安装包,解压或运行安装程序 在安装路径下创建 data\db 和 data\log 两个文件夹 创建 mongod.cfg 配置文件: systemLog: destination: file path: 安装路径\data\log\mongod.logstorage: dbPath: 安装路径\data\db 以管理员权限安装为 Windows 服务: D:\MongoDB\bin\mongod.exe --config "D:\MongoDB\mongod.cfg" --install 服务管理: net start MongoDB # 启动net stop MongoDB # 停止D:\Mong ...
SkyWalking 接入全链路追踪:第一次把服务调用看清楚了微服务架构下,A 调 B、B 再调 C 和数据库,接口最终超时了,你只知道「慢了」,不知道慢在哪一段。各服务的日志是分开的,时间戳要手动对比,效率很低。接入 SkyWalking 之后,一个请求完整的调用链路和每段耗时,在一张 Trace 图里都能看到。 接入两步走第一步:部署 OAP Server 和 UI 用 Docker Compose 快速启动: version: '3.8'services: oap: image: apache/skywalking-oap-server:9.4.0 container_name: sw-oap ports: - "11800:11800" # gRPC,Java Agent 上报数据 - "12800:12800" # REST API environment: SW_STORAGE: h2 # 测试用 H2,生产改为 elasticsearch u ...
试着学;
试着说;
试着写;
试着做;
试着,知行合一;

试着说;
试着写;
试着做;
试着,知行合一;